
A mantra of Reconfigurable Computing researchers and the ACS program is: "the performance of hardware with the flexibility of software." We have and continue to make good strides on the raw "performance" side (e.g. BRASS HSRA [FPGA99]). We are discovering raw performance bottlenecks and addressing them (e.g. GARP memory interface [FCCM97], HSRA embedded DRAM, OneChip [Jacobs98]). On many fronts, both academically and commercially, we are getting better devices with less usage restrictions. However, we are not getting most of the traditionaly benefits we normally associate with "software" systems. While this hardware can be programmed, making it "soft" in a basic sense, the hardware lacks the discipline of an organizing compute model, architecture, and run-time system. As a result, the RC systems being built today are more akin to pre-VM, pre-ISA uniprocessors than to moderm computer systems. In particular, when we think of a "general-purpose software" system today, we expect:
In order for reconfigurable computing to become a long-term viable computing paradigm, it must address these needs; truly offering the "flexibility" of software systems to integrators and end users.
The missing piece in existing RC hardware is a well defined "architecture" and compute model which will provide a consistent view of the machine regardless of implementation details, including number and composition of physical resources. The trick is to find the right computational abstractions to characterize the family of reconfigurable devices we can envision, expose a uniform view to the programmer, and represent the computation in a manner which a wide-range of hardware implementations can exploit efficiently.
The BRASS project is currently developing a stream-oriented computational model to address this issue, providing an abstract view of the reconfigurable hardware which exposes its strengths, while abstracting the actual composition of the physical resources. The key elements are:
A computation is broken up into compute pages. A compute page is the basic element of virtualization and reconfiguration. Computations are described in terms of virtual pages, which, in turn, are mapped onto physical compute pages in order to execute. When using conventional devices (e.g. XC6200), users can rewrite the configurations, but this must be done explicitly by the user and software, and, in many ways resembles overlays in early personal computers. In contrast, our virtual pages are managed by the run-time system with minimal hardware support and are similar to virtual memory management in modern computer architectures.
Link compute pages together in a dataflow manner with streams. Streams are a well-known abstraction for organizing dataflow in computer systems (e.g. [Dennis94, Dennis79, Lee/Messerschmidt87]). We use streams to represent the flow of data between pieces of computations much as traditional, serial computer systems use pointers. Like pointers, dynamic stream link creation allows the computer system to create computation and flow dynamically. Unlike pointers, stream links expose inherent opportunities for parallelism rather than obfuscating them.
Compute pages communicate through stream connections between hardware pages. A stream has multiple physical realizations: it may be a physical connection between co-resident pages, or it may be a temporal link through stream buffers in (virtual) memory. This gives us two extremes:
Configurable Memory Blocks (CMBs) are distributed in the array. These memories can hold:
I/O channels may be defined to support continuous input and output to/from the computational model.
Compute pages and stream links may be dynamically created and destroyed. This supports computations which unfold based on the run-time data. The model provides for page creation handlers, allowing specialization around creation-time bound data.
A run-time OS manager allocates and schedules pages at run-time both for computations and memory. The run-time manager and scheduler deals implicitly with varying amounts of available physical resources due to differences in physical machine size, the dynamic needs of an application, or the dynamic sharing of a physical machine amongst multiple tasks.
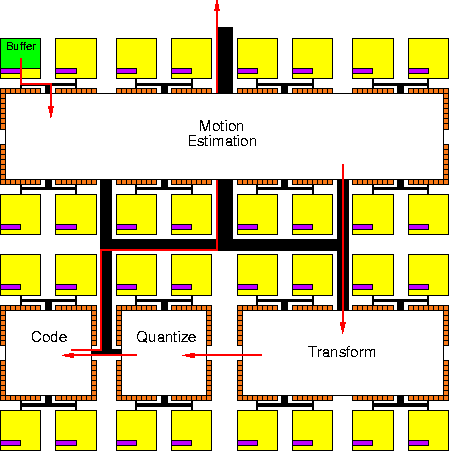
Figure 1: Spatial implementation using direct network links for stream connections
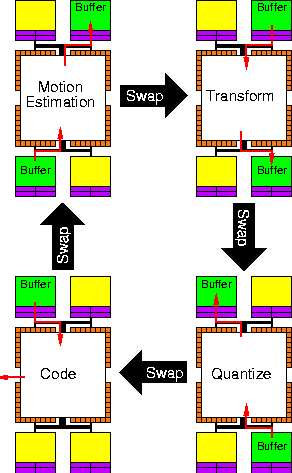
Figure 2: Sequential implementation using CMBs for stream buffers